
{kind=link}
An In-Depth Exploration of the HDLMODC-ICSA Method for Real-Time Object Recognition
Introduction to HDLMODC-ICSA
The HDLMODC-ICSA method introduces an innovative approach to object recognition designed to support visually challenged individuals. By focusing on accurate and instantaneous detection of objects in various environments, this method distinctly optimizes the interaction between technology and the visually impaired. Key components include image pre-processing, object detection (OD), feature extraction, classification, and hyperparameter tuning, all delineated in the systematic workflow shown in Figure 1.
Image Pre-processing Using Median Filtering
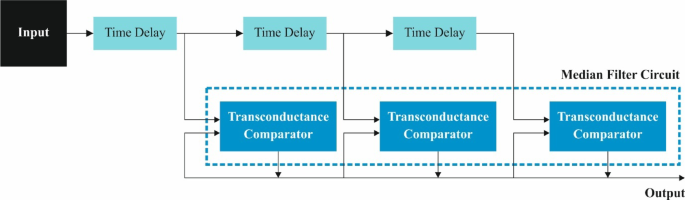
At the onset of the HDLMODC-ICSA method, image pre-processing plays a pivotal role in enhancing the quality of the images subjected to analysis. Utilizing Median Filtering (MF), the process efficiently reduces noise, particularly salt-and-pepper variations, while preserving important structural details integral for precise object identification. Unlike conventional techniques like Gaussian filtering that might blur essential features, MF’s non-linear capabilities ensure that edge details are retained, crucial for subsequent processes like object detection and feature extraction.
MF is computationally efficient and straightforward to implement, making it remarkably well-suited for real-time applications. Its balanced performance—between maintaining image integrity and reducing noise—establishes it as an optimal preliminary stage in the HDLMODC-ICSA framework.
Object Detection Using Faster R-CNN
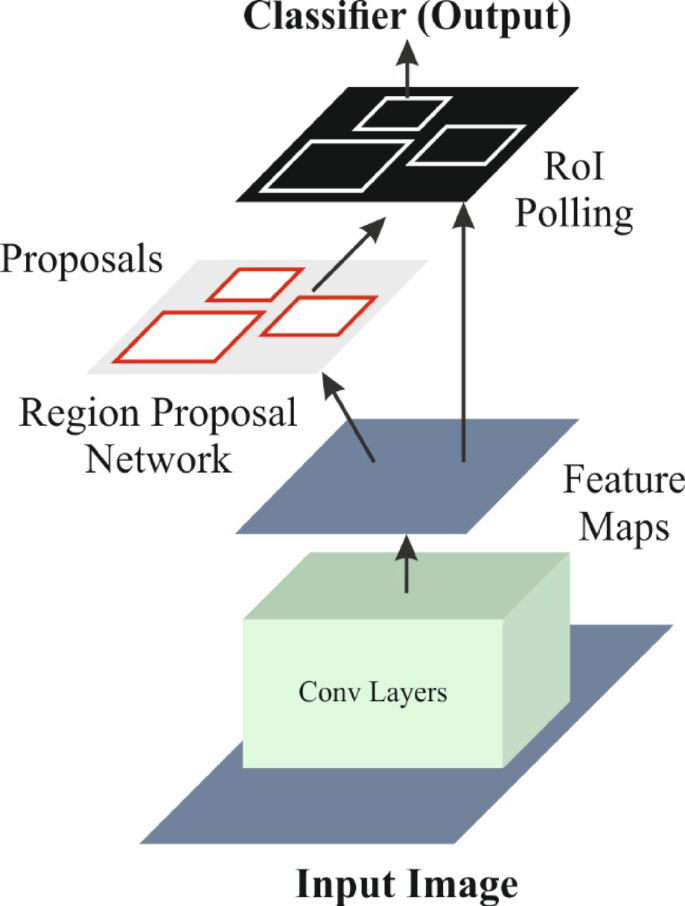
Next in the workflow is Object Detection (OD), wherein the Faster R-CNN model excels. This model stands out for its high accuracy and efficiency, adept at detecting objects across variable scales and intricate backgrounds. What differentiates Faster R-CNN from its predecessors is its unique combination of region proposal and classification into a unified, end-to-end trainable structure, notably reducing processing times.
The architecture comprises several steps:
- Base Network: Utilizes a pre-trained convolutional neural network (CNN) to extract features from the input images.
- Region Proposal Network (RPN): Quickly generates candidate object proposals by sliding windows over feature maps and adjusting bounding box coordinates.
- RoI Pooling: Transforms varying-sized candidate areas into fixed dimensions for compatibility with classification layers.
- Object Classification Networks: Classifies the proposed regions using fully connected networks to yield probabilities across multiple classes.
- Bounding Box Regression: Fine-tunes bounding box coordinates to enhance location accuracy.
This model effectively integrates two critical features: the RPN for localizing objects and the classification networks for identifying them, establishing itself as a formidable backbone for effective object detection.
The Operational Mechanism of Faster R-CNN
The operational mechanics of Faster R-CNN hinge upon several key stages. The RPN provides preliminary areas to filter through for potential objects, allowing for precise bounding box calibration and anchoring. Utilizing specifically designated loss functions, such as the Smooth L1 Loss for bounding box regression, the model ensures efficient and accurate learning of detection parameters.
The culmination of these processes results in an effective object detection capability, vital for enhancing real-world applications, particularly in aiding visually impaired individuals.
Feature Extraction with Improved LeNet-5
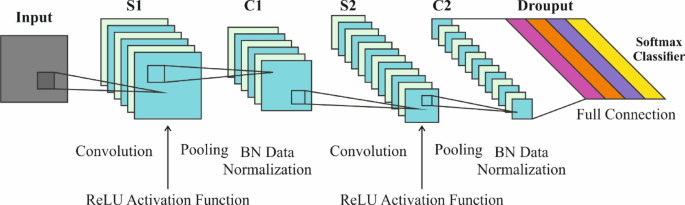
To derive meaningful features from the detected regions, the methodology transitions to the Improved LeNet-5 model. Known for its simplicity and adaptability, this model is particularly effective in capturing distinctive and complex features. Modifications to the original architecture, including the incorporation of deeper layers, advanced activation functions, and batch normalization, bolster the model’s performance while maintaining a lightweight profile.
What enhances the Improved LeNet-5 model is its ability to conduct mid-level feature extraction efficiently from the localized regions identified through the Faster R-CNN framework. Its swift training capabilities and reduced parameter count combined with robust feature representation make it an ideal candidate for integration into the HDLMODC-ICSA pipeline.
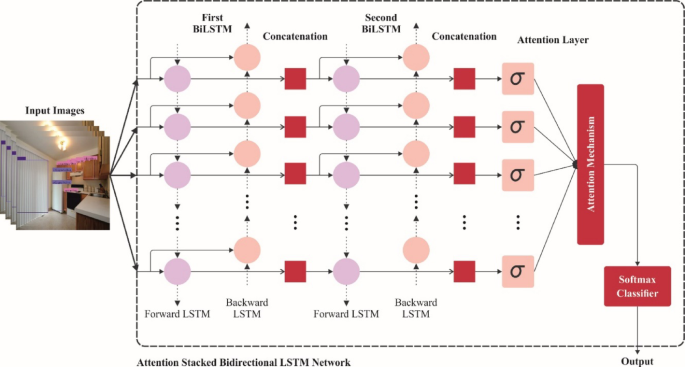
Classification Using ABS-BiLSTM Model
Subsequent to feature extraction, the ABS-BiLSTM model is employed for effective classification of the identified objects. With the capability to capture both past and future contexts within sequential data, this bi-directional architecture proves essential for uncovering intricate patterns. The incorporation of an attention mechanism amplifies the focus on significant features, leading to enhanced interpretability and accuracy.
Compared to conventional LSTM models, the ABS-BiLSTM demonstrates superior performance, particularly in scenarios characterized by variable-length input and subtle feature variations, ensuring that high-level decision-making tasks can be performed with exemplary precision.
Hyperparameter Tuning with ICSA Model
To ensure the optimized performance of the ABS-BiLSTM model, the Intelligent Crow Search Algorithm (ICSA) is utilized for hyperparameter tuning. Inspired by the natural foraging behavior of crows, this method excels at navigating the solution space to find optimal hyperparameter combinations without succumbing to local optima.
ICSA offers significant flexibility in tuning non-differentiable or complex objective functions while balancing exploration and exploitation effectively. This methodology enhances the overall model performance and generalization capacity, making it crucial in achieving a robust, adaptive system designed for real-time object recognition.
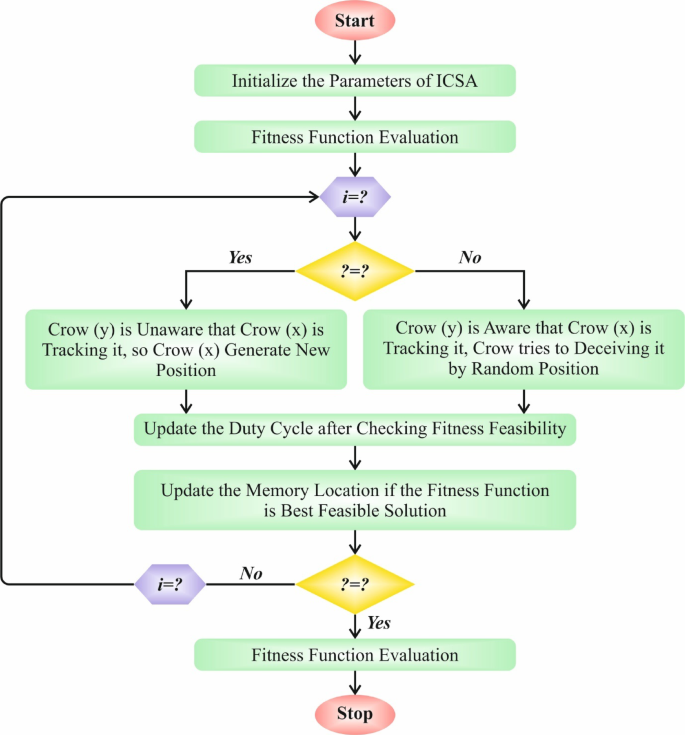
The detailed mechanics of ICSA includes population initialization, adaptive neighborhood searching, and reinforcement learning methodology, ensuring a comprehensive approach to tuning all critical parameters with efficiency and precision.
In summary, the HDLMODC-ICSA method encapsulates a robust framework for real-time object recognition aimed at greatly assisting visually impaired individuals. Through sequential image pre-processing, advanced object detection, powerful feature extraction, and precise classification coupled with fine-tuned hyperparameters, this method promises significant enhancements in object recognition capabilities.