
{kind=link}
Participants and Methods in EEG Research on Autism Spectrum Disorder
Participants
The study focused on a sample of 23 children, comprising 16 males, aged between 49 to 95 months. These participants were part of a comprehensive investigation funded by the National Institutes of Health (NICHD 2P50HD093074, Dawson, PI). The demographics of this group highlighted a predominantly White composition (17 children), with representations of Asian (2), Hispanic (4), and those identifying as mixed race or other (4). Every child in the study met the DSM-5 criteria for Autism Spectrum Disorder (ASD) as evaluated by a psychologist experienced in the Autism Diagnostic Observation Schedule-2nd Edition.
Notably, 11 out of the 23 participants were also diagnosed with co-occurring Attention Deficit/Hyperactivity Disorder (ADHD), determined through a thorough clinical assessment. The mean Full-Scale IQ of participants was noted to be 78.5 (SD = 25.5), based on the scores derived from the Differential Ability Scales Second Edition.
All legal guardians of the children provided written, informed consent before participation. The study protocol received approval from the Duke University Health System Institutional Review Board under two protocol numbers (Pro00085435 and Pro00085156). In adherence to institutional, state, and federal guidelines, all procedures followed the principles outlined in the Declaration of Helsinki. Identifying information and images were consented for publication, and any data shown in figures were anonymized.
Recording Synchronized Video and EEG
The research involved the simultaneous recording of continuous EEG and event-related potentials (ERPs). During the EEG sessions, video recordings captured the interaction of participants with a screen, showcasing their responses to various stimuli. The EEG sessions were carefully monitored; if a child was unable to adhere to the protocol, recordings were aborted. Videos varied in length from 4 minutes and 15 seconds to 31 minutes and 9 seconds, ensuring diverse responses were captured.
To maintain session quality, one or two clinical research assistants were present during recordings to gently steer the child’s attention back to the screen if distractions occurred. The child’s facial expressions were captured using a Basler ACE acA1300-30uc camera, boasting a resolution of 1296 × 966 pixels at a 30 fps frame rate. Synchronization between the camera and EEG was achieved using specialized in-house software and a Cedrus StimTracker device, which marked the EEG recordings.
Recording setup: The video and EEG recording systems were synchronized to ensure accurate data collection.
Extracting CVA Features
The extraction of CVA features (Child Visual Attention) was a multi-step process utilizing custom code developed for this study. The steps included face detection, extraction of facial landmarks and head pose angles, along with gaze estimation.
Initially, algorithms processed the video frames to determine the precise positioning of the participant’s face and vital landmarks. These landmarks included nose coordinates and head pose angles (pitch, yaw, roll). Gaze coordinates related to the screen’s plane were also estimated.
Face Detection and Disambiguation
The face_recognition Python library, utilizing the dlib C++ library, was employed for face detection and disambiguation. In instances of multiple face detections, the algorithm would present the frame to an analyst for selection of the correct participant’s face, thus minimizing errors in identification.
Extraction of Landmarks and Head Pose Angles
Once faces were accurately identified, the intraface software library extracted facial landmarks and calculated head pose angles. These calculations resulted in a comprehensive set of pixel coordinates for facial landmarks as well as head orientation angles.
For gaze estimation, the iTracker software—which was originally designed to estimate gaze on mobile devices—was adapted for use in this study. It inferred gaze coordinates within the presentation screen, although the software module could be interchanged for other gaze estimation tools.
Data Attrition and Preprocessing
Data attrition arose mainly due to a lack of focused eye contact during predetermined active periods. Analysis exclusively included segments when stimuli were presented, and only frames where facial detection was successful were included in the training set for machine learning models.
Given that inattention could manifest in various ways, features were transformed into both positive and negative representations to convey the directionality of attention (i.e., gaze off-screen or head turns). This dual representation allowed for deeper analysis of attentional shifts during recordings.
Data Labeling
Data labeling was conducted by co-authors utilizing Elan v. 6.3 software. Selecting nine participants, one annotator reviewed the frames independently. Frames were categorized based on instances of gaze deviation or head turn, and a frame was tagged as “inattention” if either behavior was displayed. The reliability of labeling was evaluated through Cohen’s kappa coefficients, ensuring high inter-annotator agreement.
Training and Evaluating Machine Learning Models
A multi-layer perceptron (MLP) model was employed to classify attention states based on the features extracted from each video frame. The model architecture consisted of an input layer with 37 features, followed by two hidden layers, and included a calibration layer for output handling.
Using weighted sampling for training, we ensured balanced attention versus inattention representations in batches. Evaluation metrics included average precision, area under the ROC curve, and maximal Cohen’s kappa for comprehensive assessments of model predictions against human annotations.
Transfer Learning: Adjusting ML Model to New Participants
The study also implemented a transfer learning approach enabling the model to adapt to new participant data efficiently. Batch selection for incremental retraining ensured the model maintained relevance for each unique subject while retaining learned features from prior training.
Agreement Measurements Between Model and Human Annotation
To quantify the agreement between human annotations and model predictions, Cohen’s kappa was again used. This quantitative analysis highlighted the effectiveness of the model and provided a framework for ongoing refinements and improvements in attentional state detection.
User-Friendly Interface for Visualization and Retraining
A user-friendly web-based graphical interface was created to facilitate data visualization, manual labeling, and model retraining. This tool enabled researchers and practitioners to engage with the data directly, fostering a collaborative approach to model improvements based on real-time feedback.
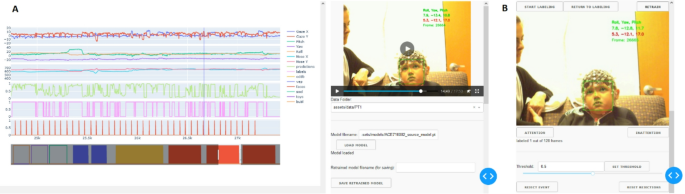
Graphical User Interface: Visualization and manual labeling features enhance the researchers’ ability to refine model performance.
This structure provided a comprehensive overview of how technology and methodology intertwine within the research of attentional behaviors in children with ASD, offering valuable insights for future studies and interventions.