
{kind=link}
Author Identification: A Comprehensive Overview of Data and Methodology
The Data: Understanding Textual Foundations
In the world of author identification, the datasets used form the backbone of any analysis. This research leverages two distinct datasets to gauge the performance of the proposed author identification model.
Set A: Rich Literary Texts
The first dataset, hereafter referred to as Set A, serves as a robust foundation for testing the model. It consists of the literary works of four authors, each equipped with at least 100 text samples. Each sample boasts a length of no less than 8000 characters, ensuring a rich tapestry of language, punctuation, and stylistic elements. The samples encapsulate a variety of genres, including novels, essays, and prose, totaling a remarkable 420 text samples. This assortment allows for a thorough exploration of each author’s distinctive writing style, thereby providing ample data for model training and evaluation.
Set B: A Broader Challenge
Conversely, Set B encompasses a more extensive palette, featuring works from 30 authors, with each contributing 30 samples. While this set includes a variety of genres such as novels, articles, prose, poems, and reports, each sample is notably shorter, containing a minimum of 1500 characters. This distinction results in 900 text samples altogether. The increased author variety, alongside fewer samples per author and a reduced average sample length, presents a uniquely challenging scenario for author detection. This element mirrors real-world conditions more accurately, allowing the proposed model to be tested under varied circumstances.
The Proposed Method: A Multifaceted Approach
The intricate nature of author identification demands more than a single approach or dataset. Accordingly, this research embraces a multifaceted methodology aimed at enhancing accuracy and generalizability. By integrating various feature extraction techniques and multiple learning models, the proposed method aims to establish a high-performance author identification system.
Methodological Steps
The proposed method comprises three fundamental steps:
- Pre-processing of Texts
- Feature Representation
- Classification
Each step plays a crucial role in sharpening the model’s effectiveness.
Pre-processing of Texts
The preprocessing stage lays the groundwork for accurate analysis. It involves transforming raw text into a structured format, effectively segmenting it into paragraphs, sentences, and individual words. This standardization corrects inconsistencies in spacing, punctuation, and common symbols, ensuring a uniform approach to subsequent analyses. The process also involves replacing specific entities—like numbers, email addresses, and web URLs—with standardized keywords, enhancing the model’s focus on meaningful textual elements.
Representing Text Features
In the second phase, three disparate techniques are harnessed for feature representation:
- Statistical Features
- TF-IDF Technique
- Word2Vec Technique
This combination captures a broad spectrum of writing patterns and styles, ensuring a robust feature set.
Extracting Statistical Features
Statistical features provide a numerical representation of a text’s stylistic elements, derived through careful analysis of its sentences and grammatical structures. Key features include:
- Average Sentence Length
- Proportion of Ineffective Words
- Grammatical Role Frequency
- Punctuation Usage Rate
- Average Word Length
Each of these features forms a comprehensive vector that encapsulates critical stylistic attributes, which will later be utilized by the CNN (Convolutional Neural Network) components.
TF-IDF Features: Weighting Words
The TF-IDF (Term Frequency-Inverse Document Frequency) method assesses the significance of words within a text based on their occurrence. This feature extraction process includes:
- Removing Ineffective Words: Filtering out common terms that contribute little semantic value, like "and" and "the."
- Word Stemming: Reducing words to their root forms to consolidate variations (e.g., "running" vs. "run").
- Vector Calculation: Each document is represented by a TF-IDF vector, denoting the weighted importance of its keywords.
Word2Vec Features: Semantic Representation
The Word2Vec model introduces another layer of depth, translating words into vectors that encapsulate their semantic meanings. Utilizing the Skip-Gram technique, the model predicts surrounding words given a target word, thus creating a rich representation of relationships between words. The resulting vectors serve as inputs for one of the CNN models, enhancing the model’s ability to capture nuanced writing styles through contextual understanding.
Classification and Author Recognition
After generating feature vectors through statistical analysis, TF-IDF, and Word2Vec techniques, the next step is classification. Each feature set feeds into a separate CNN model, adept at learning unique authorship patterns.
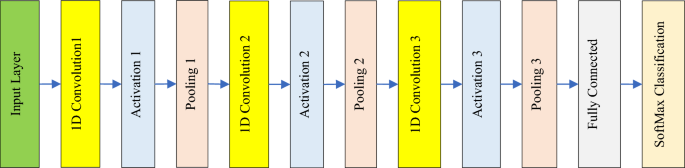
The Structure of CNN Components
Each CNN model consists of three one-dimensional convolution blocks, employing similar architectures but distinct configurations tailored to the specific feature type being analyzed. Each model concludes with a fully connected layer followed by a classification layer that determines the target class—essentially the author of the examined text.
Aggregating Results for Final Identification
The journey from feature extraction to classification culminates in a novel aggregation of results. Recognizing challenges in traditional ensemble learning—such as managing multiple target classes and similar writing styles—the proposed method employs a machine learning model for output integration rather than basic strategies like majority voting.
In this innovative approach, outputs from the CNNs are represented through their respective classification weights and training accuracies. These vectors then undergo a weighted, dynamic combination via a self-attention mechanism, which allows for nuanced decision-making based on the output relevance of each model concerning the task at hand.
Through this intricate process, the model effectively learns to harness the strengths of each feature representation, ultimately yielding a highly discriminative fused feature vector. This comprehensive vector serves as the final input to a SoftMax classifier, culminating in the identification of the text’s author.
The methodology, intricately interwoven with sophisticated feature extraction and machine learning techniques, exemplifies a monumental leap toward enhanced accuracy in author identification, thereby paving the way for future advancements in the field.